xarray Groupby#
Lesson Content
groupby
groupby bins
Context#
Yesterday we began to explore working with data in xarray. Today we are going to dig into that even deeper with a concept called groupby. Groupby is going to allow us to split our data up into different categories and analyze them based on those categories. It sounds a bit abstract right now, but just wait - it’s powerful!
import xarray as xr
sst = xr.open_dataset("https://www.ncei.noaa.gov/thredds/dodsC/OisstBase/NetCDF/V2.1/AVHRR/198210/oisst-avhrr-v02r01.19821007.nc")
sst = sst['sst'].squeeze(dim='zlev', drop=True)
Groupby#
While we have lots of individual gridpoints in our dataset, sometimes we don’t care about each individual reading. Instead we probably care about the aggregate of a specific group of readings.
For example:
Given the average temperature of every county in the US, what is the average temperature in each state?
Given a list of the opening dates of every Chuck E Cheese stores, how many Chuck E Cheeses were opened each year? 🧀
In xarray we answer questions like that that with groupby.
Breaking groupby into conceptual parts#
In addition to the dataframe, there are three main parts to a groupby:
Which variable we want to group together
How we want to group
The variable we want to see in the end
Without getting into syntax yet we can start by identifiying these in our two example questions.
Given the average temperature of every county in the US, what is the average temperature in each state?
Which variable to group together? -> We want to group counties into states
How do we want to group? -> Take the average
What variable do we want to look at? Temperature
Given a list of the opening dates of every Chuck E Cheese stores, how many Chuck E Cheeses were opened each year?
Which variable to group together? -> We want to group individual days into years
How do we want to group? -> Count them
What variable do we want to look at? Number of stores
📝 Check your understanding
Identify each of three main groupby parts in the following scenario:
Given the hourly temperatures for a location over the course of a month, what were the daily highs?
Which variable to group together?
How do we want to group?
What variable do we want to look at?
groupby syntax#
We can take these groupby concepts and translate them into syntax. The first two parts (which variable to group & how do we want to group) are required for pandas. The third one is optional.
Starting with just the two required variables, the general syntax is:
DATAFRAME.groupby(WHICH_GROUP).AGGREGATION()
Words in all capitals are variables. We’ll go into each part a little more below.
# We only have 1 month, so this doesn't fly here maybe on homework?
sst.groupby('time.month').mean()
<xarray.DataArray 'sst' (month: 1, lat: 720, lon: 1440)> Size: 4MB
array([[[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
...,
[-1.1899999, -1.1899999, -1.1899999, ..., -1.1899999,
-1.1899999, -1.1899999],
[-1.1899999, -1.1899999, -1.1899999, ..., -1.1899999,
-1.1899999, -1.1899999],
[-1.1899999, -1.1899999, -1.1899999, ..., -1.1899999,
-1.1899999, -1.1899999]]], dtype=float32)
Coordinates:
* lat (lat) float32 3kB -89.88 -89.62 -89.38 -89.12 ... 89.38 89.62 89.88
* lon (lon) float32 6kB 0.125 0.375 0.625 0.875 ... 359.4 359.6 359.9
* month (month) int64 8B 10
Attributes:
long_name: Daily sea surface temperature
units: Celsius
valid_min: -300
valid_max: 4500
_ChunkSizes: [ 1 1 720 1440]'WHICH_GROUP'#
This can be any of the dimensions of your dataset. In physical oceanography, for example, it is common to group by latitude, so that you can see how a variable changes as you move closer to or further away from the equator.
sst.groupby('lat').mean(...)
<xarray.DataArray 'sst' (lat: 720)> Size: 3kB
array([ nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, nan, nan,
nan, nan, -1.51692545e+00, -1.53166163e+00,
-1.55314803e+00, -1.57018578e+00, -1.58648872e+00, -1.59056687e+00,
-1.59533644e+00, -1.61027491e+00, -1.63276756e+00, -1.64728677e+00,
-1.65520298e+00, -1.65427852e+00, -1.65435839e+00, -1.63652658e+00,
-1.64526653e+00, -1.62598121e+00, -1.63246810e+00, -1.65207720e+00,
-1.67231202e+00, -1.67294431e+00, -1.67326570e+00, -1.65209937e+00,
-1.64746594e+00, -1.65392554e+00, -1.66650736e+00, -1.67372000e+00,
-1.67431283e+00, -1.67534673e+00, -1.67392111e+00, -1.66620767e+00,
-1.66788197e+00, -1.66215205e+00, -1.65882778e+00, -1.65802705e+00,
...
1.60739243e+00, 1.40621614e+00, 1.21297944e+00, 1.08243787e+00,
9.51626182e-01, 8.30649316e-01, 7.59354472e-01, 6.84241772e-01,
5.59581220e-01, 4.71847862e-01, 3.53565305e-01, 1.82334155e-01,
4.14617620e-02, -5.61492406e-02, -1.36128768e-01, -1.94080502e-01,
-1.99803725e-01, -2.02549189e-01, -2.60961652e-01, -3.16458732e-01,
-4.41025198e-01, -5.69864333e-01, -6.84798598e-01, -7.52268255e-01,
-8.07088614e-01, -8.45351577e-01, -8.26967835e-01, -8.53520334e-01,
-8.92809749e-01, -9.03403878e-01, -9.43648040e-01, -1.00938070e+00,
-1.06675816e+00, -1.13523424e+00, -1.16256773e+00, -1.09204960e+00,
-1.07783961e+00, -1.06503558e+00, -1.09915543e+00, -1.12950075e+00,
-1.14294803e+00, -1.16515660e+00, -1.17709863e+00, -1.18073034e+00,
-1.18820989e+00, -1.18804479e+00, -1.18709540e+00, -1.19452322e+00,
-1.20153499e+00, -1.20324004e+00, -1.20159030e+00, -1.19786119e+00,
-1.19466662e+00, -1.19252777e+00, -1.19127083e+00, -1.19085419e+00,
-1.19068754e+00, -1.19081247e+00, -1.19086802e+00, -1.19065273e+00,
-1.19079852e+00, -1.19093740e+00, -1.19086802e+00, -1.19090283e+00,
-1.19074309e+00, -1.19078469e+00, -1.19062495e+00, -1.19081247e+00,
-1.19086802e+00, -1.19059026e+00, -1.19079852e+00, -1.19078469e+00,
-1.19057631e+00, -1.19061089e+00, -1.18999982e+00, -1.18999982e+00],
dtype=float32)
Coordinates:
* lat (lat) float32 3kB -89.88 -89.62 -89.38 -89.12 ... 89.38 89.62 89.88
Attributes:
long_name: Daily sea surface temperature
units: Celsius
valid_min: -300
valid_max: 4500
_ChunkSizes: [ 1 1 720 1440]AGGREGATION#
The goal with each of the groups of data is to end up with a single value for the things in that group. To tell xarray how to gather the datapoints together we specify which function we would like it to use. Any of the aggregation functions we talked about at the beginning of the lesson work for this!
sst.groupby('lat').mean(...).plot()
[<matplotlib.lines.Line2D at 0x7fb9b7b4ce10>]
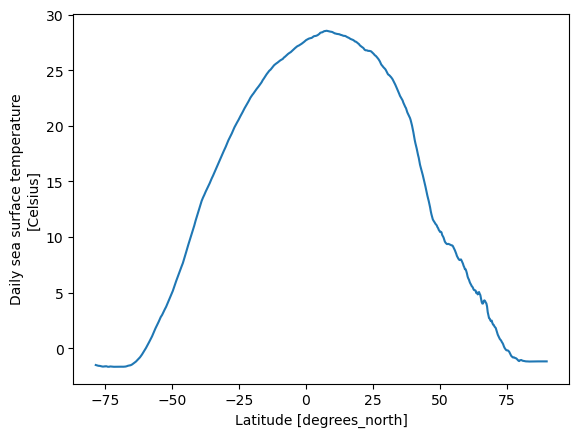
What do we see? Hot water near the equator and chilly water near the poles.
Note
The ellipses ... inside the .mean() tell xarray to take the mean over all of the remaining axis. You wouldn’t have to do that - you may instead want to take the mean over just the latitude and keep the time resolution. It’s quite common, though, to want to aggregate over all remaining axis.
time dimension#
If your data has a time dimension and it is formatted as a datetime object you can take advantage of some slick grouping capabilities. For example, you can group by a time group like 'time.month', which will grab all make 12 groups for you, putting all the data from each month into its own group.
# We only have 1 month, so this doesn't fly here maybe on homework?
sst.groupby('time.month').mean()
<xarray.DataArray 'sst' (month: 1, lat: 720, lon: 1440)> Size: 4MB
array([[[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
[ nan, nan, nan, ..., nan,
nan, nan],
...,
[-1.1899999, -1.1899999, -1.1899999, ..., -1.1899999,
-1.1899999, -1.1899999],
[-1.1899999, -1.1899999, -1.1899999, ..., -1.1899999,
-1.1899999, -1.1899999],
[-1.1899999, -1.1899999, -1.1899999, ..., -1.1899999,
-1.1899999, -1.1899999]]], dtype=float32)
Coordinates:
* lat (lat) float32 3kB -89.88 -89.62 -89.38 -89.12 ... 89.38 89.62 89.88
* lon (lon) float32 6kB 0.125 0.375 0.625 0.875 ... 359.4 359.6 359.9
* month (month) int64 8B 10
Attributes:
long_name: Daily sea surface temperature
units: Celsius
valid_min: -300
valid_max: 4500
_ChunkSizes: [ 1 1 720 1440]groupby bins#
Breaking down the process#
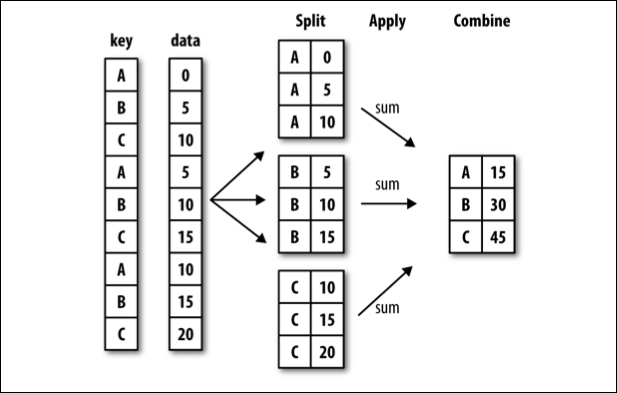
There is a lot that happens in a single step with groupby and it can be a lot to take in. One way to mentally situate this process is to think about split-apply-combine.
split-apply-combine breaks down the groupby process into those three steps:
SPLIT the full data set into groups. Split is related to the question Which variable to group together?
APPLY the aggregation function to the individual groups. Apply is related to the question How do we want to group?
COMBINE the aggregated data into a new dataframe